TRADEOFF Graffiti: Version Numbers
TRADEOFF Graffiti for Version Numbers
Playing with this resulted innovization (innovation through optimization efforts) a new version number schema that combines benefits of Sem Version, Date Time Strings and UUIDs. This is depicted in the diagram as SemDateTime. It also helped me discover and articulate the higher order trade offs in the green boxes. While documenting them, I believe I discovered a new way of doing it (marked with the lightning bolt in the visual).
Problem One: Human Compatibility Over Machines-Required Compatibility
Semantic Versions comprised of date components have a format that is recognizable to humans, can be attached to an absolute point in time, can use existing dates from artifacts or other revision systems, can be compared directly by humans and for which most languages have built-in comparison operators. Importantly, they retain theses benefits while still being able to handle multiple, near-simultaneous, unique version generations in a very busy repository. This last requirement is frequently the reason for embracing abstract versioning that is not friendly to human handling and processing of the version number.
Using portions of dates for a semver are not the key innovation and you've probably seen them before as CalVer
Problem Two: Deterministic, No-Coordination Required, Next Version Generation
ChronoVer also solves a second, thorny problem in a very simple way. That problem is "next version number" generation with no accidental overlap, in a repository that is very busy. The most sophisticated tool for solving this problem today is probably GitVersion. GitVersion's sophistication comes with the tradeoff of potential complexity.
SemVerDate handles this by simply tracking fractional seconds since midnight of the day of generation.
The CI/CD Component referenced below is capable of tracking Nanoseconds - 9 decimal positions.
High Cost of Inhumane Version Numbers
If we could track the cost of version numbers that are not easy for humans to understand, compare and type - I think we'd be set back on our heals. Small copy paste errors, look up tables for sequencing of numbers and many other problems can be avoided through making version numbers humane.
Tradeoff Analsis
The following TRADEOFF Graffiti formatted visuals reflect the tradeoffs of some of the major approaches taken to version numbers.
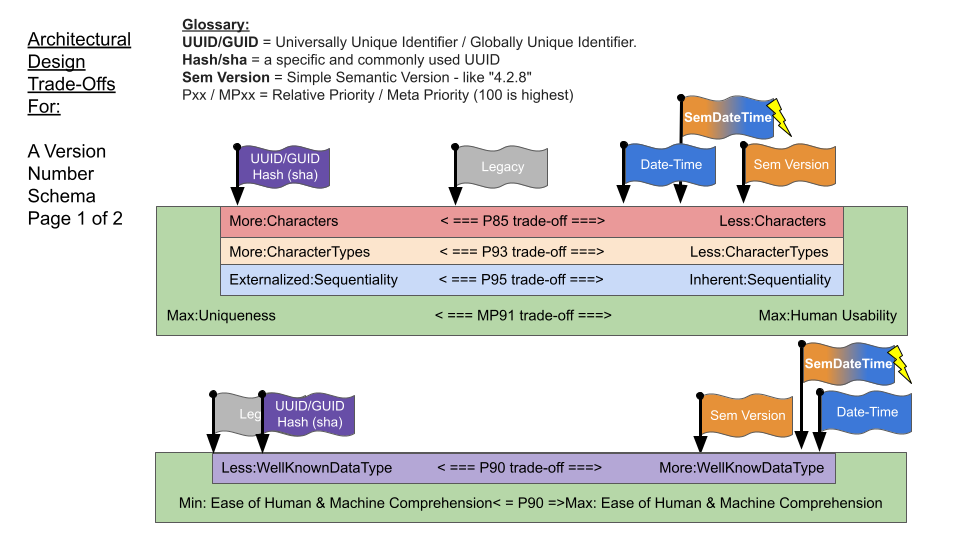
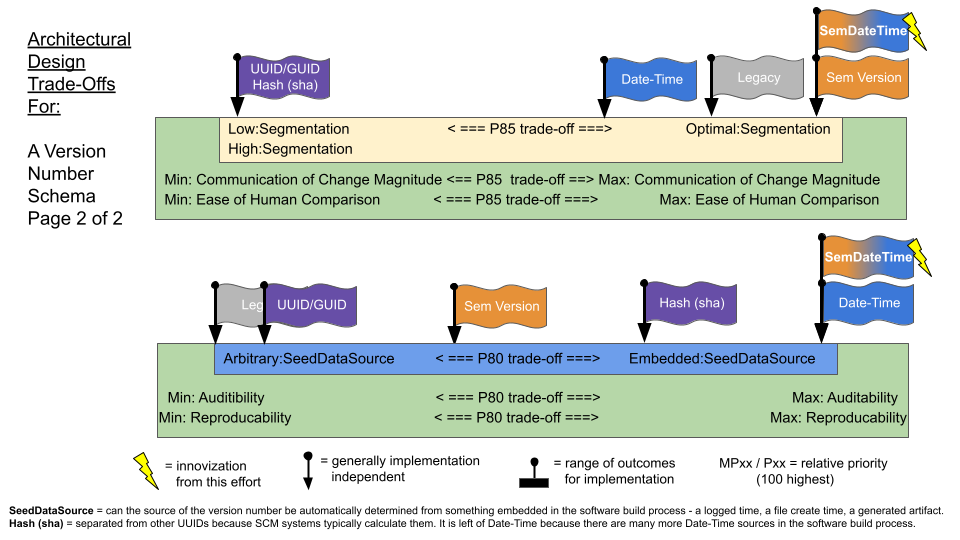
Top Level Architectural Trade-offs
| Versioning Structure & Operations | Primary Architectural Trade-off |
|---|---|
| Schema Orientation1 | machine only or human inclusive <= favorable |
| Schema Relativity2 | Relative or Absolute <= favorable |
| Seed Source3 | Algorithm or Embedded <= favorable |
| Store / Retrieve4 | External or Embeddable Metadata <= favorable |
| Discover Latest5 | Enumeration or Deterministic <= favorable |
| Compare6 | machine or Humane <= favorable |
| Compare Algorithms7 | Contrived or inherent <= favorable |
Explanation
- Schema Orientation: GUIDs, UUIDs and SHAs as a primary version are machine oriented to an inhumane degree because they are too long and require extensive, external searching to do basic sequential comparison.
- Schema Relativity: Relative is like “Incrementing the Last version” while Absolute would be basing it on the date and time. Absolute benefits from not needing uniqueness coordination across branches, systems, across time, etc.
- Seed Source: An example of an Embedded Seed Source is a git commit hash or an SCM commit date - both already happen in an existing system as a part of other necessary operations and so do not require any code algorithms to generate a new version number. Embedded creation can only be in one source and then needs to be propagated to others. For instance a git commit as a date source for version must be manually tagged and labeled to a container since you would not / could not force the container publish date to match the git commit date. Embedded generation may also preserve the most detailed version number (e.g. milliseconds granularity of a datetime stamp) even if not frequently used. Commit hashes do not satisfy the need for humane version comparison operations, but are noted here as Embedded Generation.
- Store / Retrieve: Embeddable means that a given system already has a schema that can be leveraged for storing versions - like git tags, docker tags and labels, etc.
- Discover Latest: Storage options requiring enumeration to manually find the latest version by sorting are so painful they should be traded for those that do not whenever possible. Sometimes existing systems can be configured to be deterministic - for instance, encoding version as a LABEL in docker containers so that retrieving the “latest” TAG gives a deterministic “latest version” - even though versions must ALSO be tags.
- Compare: Humane comparisons can be done by humans in their head without the assistance of code.
- Compare algorithms: that involve dates are already available (inherent) in almost every coding language available. Contrived schemes like Sem Version require libraries (especially if prereleases alpha characters must be supported). A four segment version number can accommodate a date based schema to seconds or milliseconds granularity and can then use date comparisons after a little reparsing. Date and time comparisons are inherent to humans.
GitLab CI/CD Component for ChronoVer Using System Date
The ChronoVer GitLab CI/CD Component enables easy version generation according to this new method. The generated version is available to all other jobs in the pipeline for use in versioning anything - including binaries, packages and releases.
Sample Code
Git only tracks to seconds granularity.
Most Operating System date retrievals can go as far as nanoseconds.
NTPv4 (64-bit) has a much, much higher resolution.
Seconds granularity for SemDate should be "As low as possible, while still avoiding version generation overlap in the same versioning scope". Version generation overlap happens only when two simultaneous, but independent process generate a supposedly unique version in the same 'moment'. It should be as low as possible to be "more humane" - as easy as possible for humans to remember, calculate and transcribe.
In software version numbers, super busy repositories many need to support milliseconds or higher. Low activity repositories could use just "seconds". It's only about avoiding simultaneous identical version number generation on independent work activities - which involves a measure of the risk of version numbers being simultaneously generated.
#YYYY.MM.DD.SS (Since midnight) No leading zeros from a Git Tag
TAG=v1.1.0 ; echo $(date -d @“$(git show $TAG -s --format=%ct)” +“%Y.%-m.%-d”).$(( $(date -d @“$(git show $TAG -s --format=%ct)” +“((10#%H * 60) + 10#%M) + 10#%S”) ))
#YYYY.MMDD.SS (Since midnight) From Git Tag, semver compliance by combining MM and DD for 3 position numeric with no leading zeros
TAG=v1.1.0 ; echo $(date -d @“$(git show $TAG -s --format=%ct)” +“%Y.%-m%-d”).$(( $(date -d @“$(git show $TAG -s --format=%ct)” +“((10#%H * 60) + 10#%M) + 10#%S”) ))
#MAJOR.MMDD.SS (since midnight). From Git Tag, semver compliant for compares. Force a major instead of the year - major must increment at least yearly.
TAG=v1.1.0 ; MAJOR=7 ; echo $(date -d @“$(git show $TAG -s --format=%ct)” +“$MAJOR.%-m%-d”).$(( $(date -d @“$(git show $TAG -s --format=%ct)” +“((10#%H * 60) + 10#%M) + 10#%S”) ))